I have a problem with one of my webhooks.
It looks like it disables itself but in the UI it still shows the workflow as active.
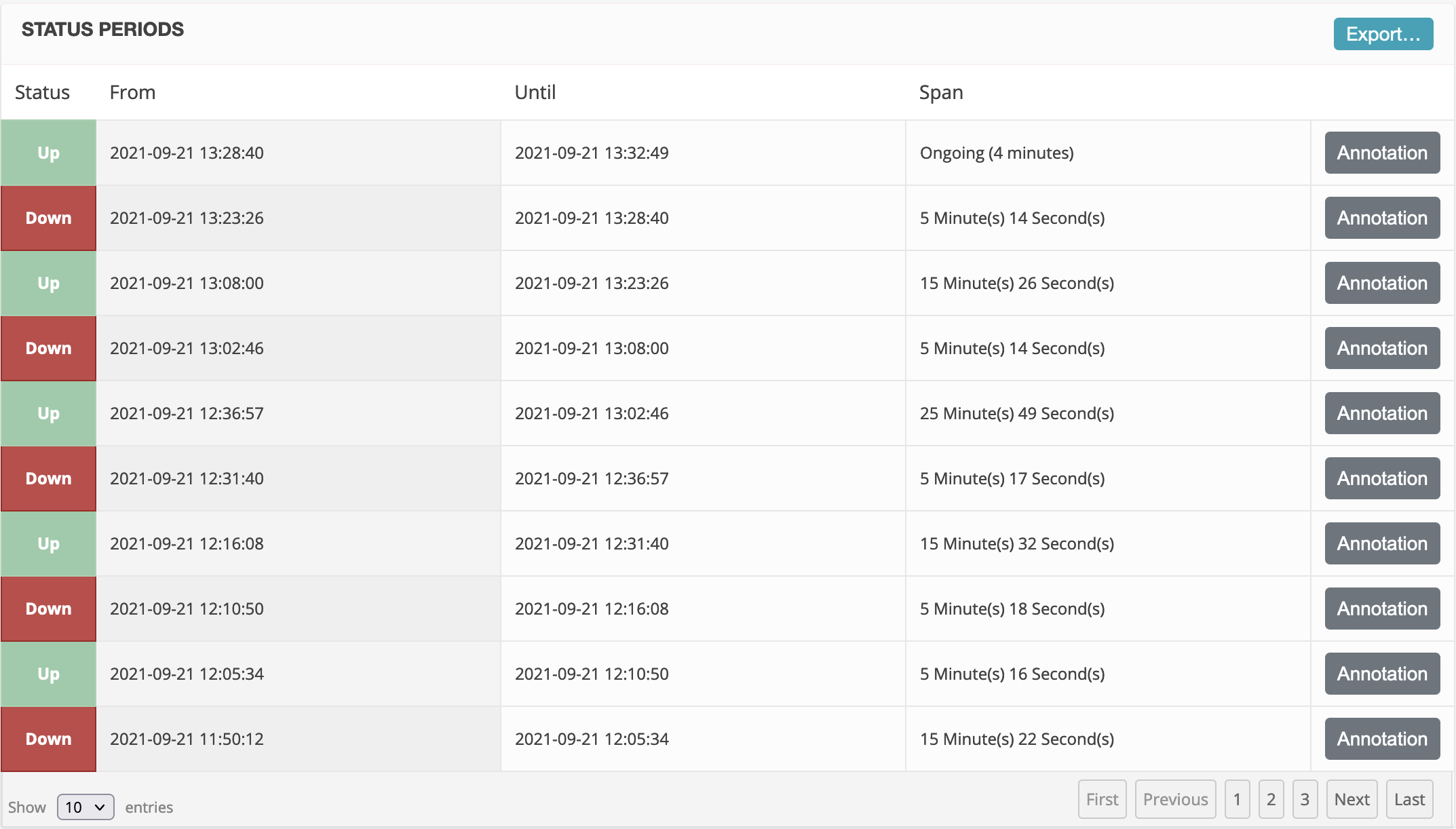
This is our status log just from today:
About our setup, it is running on a Kubernetes cluster and is connected to a Postgres database.
In the logs is no sign of any changes that could disable the workflow.
Is there anything that I could do to restart to workflow when the webhook gets disabled?
Well, you say you’re running a Kubernetes cluster, so I believe you have multiple n8n instances, right? In this case, I would like to ask you if you are using “webhook” processes or just running multiple “regular” n8n instances. If you’re not sure what “webhook” processes are, I would recommend checking our Scaling guide.
Still, even if you’re not using “webhook” instances it should be running just fine. Can you confirm that your cluster is running fine and there is no networking issue? Do you have heavy traffic coming to these instances? If n8n receives too much traffic at once it might crash, maybe justifying it being offline.
Lastly, have you set the EXECUTION_PROCESS setting to something or is it using default?
These items will help us see what can be happening.
# The n8n related part of the config
config:
port: 5678
generic:
timezone: Europe/London
database:
type: postgresdb
security:
basicAuth:
active: true
secret:
database:
postgresdb:
password: ""
##
##
## Common Kubernetes Config Settings
persistence:
## If true, use a Persistent Volume Claim, If false, use emptyDir
##
enabled: true
type: emptyDir # what type volume, possible options are [existing, emptyDir, dynamic] dynamic for Dynamic Volume Provisioning, existing for using an existing Claim
## Persistent Volume Storage Class
## If defined, storageClassName: <storageClass>
## If set to "-", storageClassName: "", which disables dynamic provisioning
## If undefined (the default) or set to null, no storageClassName spec is
## set, choosing the default provisioner. (gp2 on AWS, standard on
## GKE, AWS & OpenStack)
##
# storageClass: "-"
## PVC annotations
#
# If you need this annotation include it under values.yml file and pvc.yml template will add it.
# This is not maintained at Helm v3 anymore.
# https://github.com/8gears/n8n-helm-chart/issues/8
#
# annotations:
# helm.sh/resource-policy: keep
## Persistent Volume Access Mode
##
accessModes:
- ReadWriteOnce
## Persistent Volume size
##
size: 1Gi
## Use an existing PVC
##
# existingClaim:
# Set additional environment variables on the Deployment
extraEnv:
VUE_APP_URL_BASE_API: https://***/
WEBHOOK_TUNNEL_URL: https://***/
# Set this if running behind a reverse proxy and the external port is different from the port n8n runs on
# WEBHOOK_TUNNEL_URL: "https://n8n.myhost.com/
replicaCount: 1
image:
repository: n8nio/n8n
pullPolicy: IfNotPresent
# Overrides the image tag whose default is the chart appVersion.
tag: ""
imagePullSecrets: []
nameOverride: ""
fullnameOverride: ""
serviceAccount:
# Specifies whether a service account should be created
create: true
# Annotations to add to the service account
annotations: {}
# The name of the service account to use.
# If not set and create is true, a name is generated using the fullname template
name: ""
podAnnotations: {}
podSecurityContext: {}
# fsGroup: 2000
securityContext:
{}
# capabilities:
# drop:
# - ALL
# readOnlyRootFilesystem: true
# runAsNonRoot: true
# runAsUser: 1000
service:
type: NodePort
port: 80
annotations:
cloud.google.com/backend-config: '{"ports": {"80":"n8n-backendconfig"}}'
ingress:
enabled: false
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
hosts:
- host: chart-example.local
paths: []
tls: []
# - secretName: chart-example-tls
# hosts:
# - chart-example.local
resources:
# We usually recommend not to specify default resources and to leave this as a conscious
# choice for the user. This also increases chances charts run on environments with little
# resources, such as Minikube. If you do want to specify resources, uncomment the following
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
limits:
cpu: 1
memory: 4G
requests:
cpu: 250m
memory: 250M
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 80
# targetMemoryUtilizationPercentage: 80
nodeSelector: {}
tolerations: []
affinity: {}
as you can see in the config it is set at the moment to 1 replica so not multiple instances. To your point, if there is heavy traffic on the workflow, we have at the moment 3 clients that call the webhook every 5 minutes. Could it be that it breaks when all three call at the same time?
Interesting, it doesn’t seem to be setting anything as default. It let’s n8n defaults in place.
Can you confirm that it’s getting deactivated? Are you getting a 404 error saying “webhook path xyz is not registered”?
Also one important note is to set the configuration N8N_SKIP_WEBHOOK_DEREGISTRATION_SHUTDOWN=true so that n8n does not deregister the webhooks once it is shut down or scaled.
I have not found a sign of a similar log, but I will keep searching and keep you posted.
The good news is the webhook was alive all day with the new flag set.
I wanted to check in and see if you’re facing the issue or is it solved? If it’s solved, can you please share the solution (or mark the solution that helped)?
Sorry, I forgot to mark the solution. Wanted to monitor first that everything is working,
but it is all solid since I added the flag krynble mentioned.