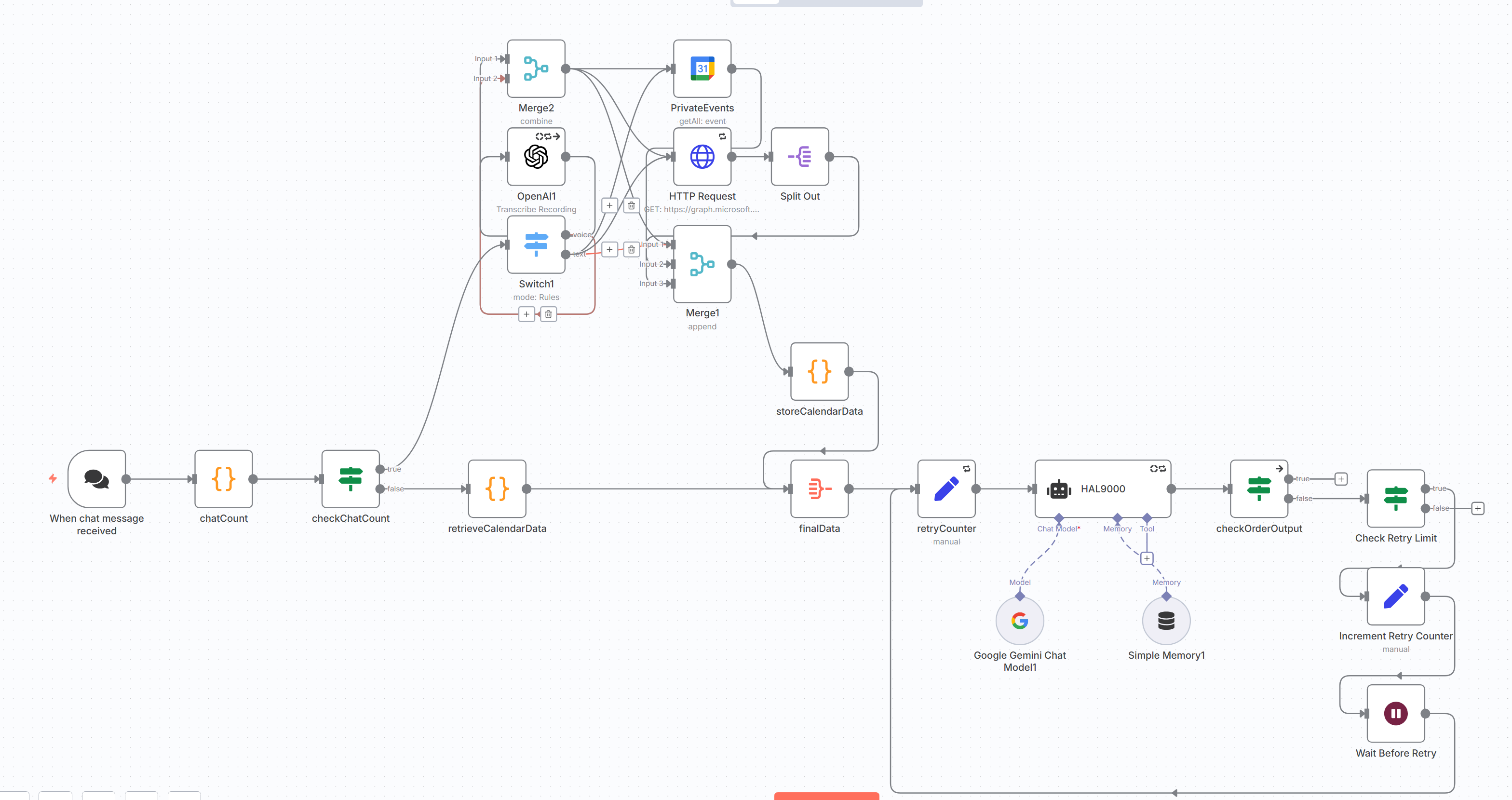
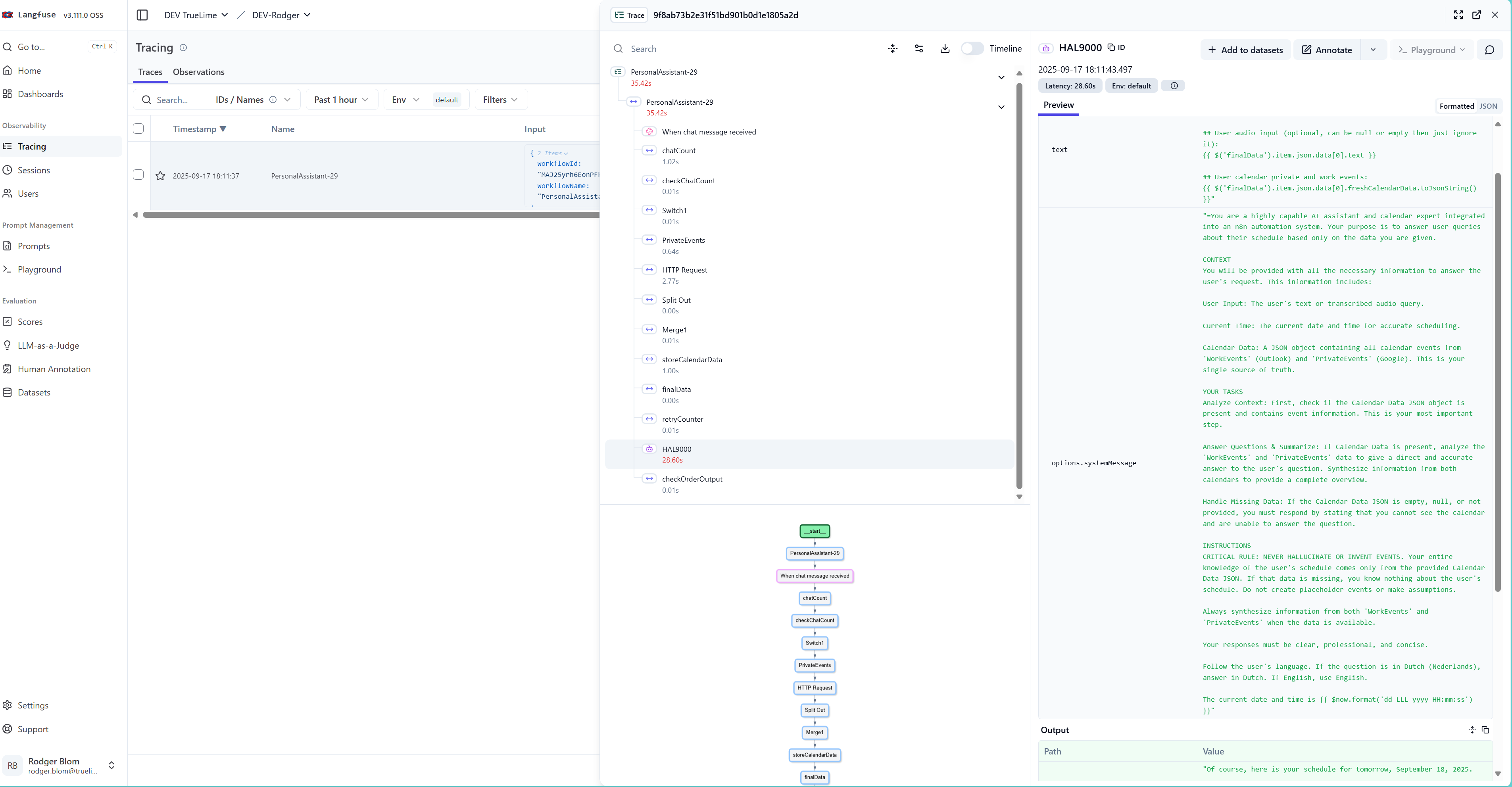
I hacked this to work with Helicone and Langfuse. Works with n8n cloud and doesn’t require you to self host and create a custom node.
Here is what you can do:
Step 1 - create an API proxy which will sit between a call from n8n and the LLM and observation platform (Helicone, Langfuse, etc).
- Create a new proxy API with whatever cloud platform you work with or deploy with FastAPI. I use GCP Cloud Functions. This API can accept /models and /chat/completions end points, which is what n8n uses to authenticate and route model requests when using the OpenAI node (we’ll be modifying this later to make it a node for our proxy)
- This API will simply take the body from n8n request, and forward it over to the Helicone URL or you could route it directly to OpenRouter. I opted for OpenRouter with Helicone so I can easily send different models vs just OpenAI. If you use LangFuse, this is also where you could add your tracing code.
- I inject the necessary headers to make Helicone work but other than that the body is passed over from n8n with no major transformations.
- You have to handle SSE streaming responses since now n8n is sending this flag as true which was surprising to see when I logged the json sent from n8n.
Step 2 - configure your new API as the base URL in the OpenAI node
- Create a new OpenAI auth credential in n8n. Change the base URL to your API URL that you just created above. It will attempt to auth with /models which will be appended to the base URL. As long as you handle that and return a 200 response, it will work. You could put in whatever you want for the API key here.
Step 3 - add OpenAI node to your agent or LLM chain
- Now create an OpenAI node and connect to one of your agents. Select the new credential you just created.
- Change the model name to match the open router naming conventions => openai/{model_name}
- Since we’re routing this in our proxy to open router then this node is now really an open router node that send data first to our proxy.
Step 4 - optionally pass a session id
- Add the response format option in the OpenAI node and set it as an expression. Pull in the session id so you can pass this along to Helicone or Langfuse. This is a bit hacky no doubt but no other way to send in other data unless you wanted to start parsing the system or user prompt. I just strip this out and don’t forward it along and then save the session id and map to the Helicone session id header.
Thats pretty much it. Here’s the sample code for your proxy API in JS that I use to make this work with Helicone.
/**
* Responds to HTTP requests for /models and /chat/completions paths.
* Handles SSE streaming for /chat/completions if stream: true is in the request.
* Sends Helicone-Session-Id and other Helicone-specific headers using request-specific headers with client.chat.completions.create().
*
* @param {!express:Request} req HTTP request context.
* @param {!express:Response} res HTTP response context.
*/
// Import the OpenAI library.
// Make sure to add "openai" to your package.json dependencies.
const OpenAI = require("openai");
// Initialize the OpenAI client.
// IMPORTANT: Set the OPENROUTER_API_KEY environment variable in your Cloud Function's configuration.
const client = new OpenAI({
apiKey: process.env.OPENROUTER_API_KEY, // Env variable that stores my key
baseURL: "https://openrouter.helicone.ai/api/v1",
defaultHeaders: {
"Helicone-Auth": "Bearer {{YOUR API KEY HERE}}" // Replace with your actual Helicone API key. I was working fast and didn't move this to env var yet }
});
exports.proxy = async (req, res) => {
// Log the request path for debugging
console.log('Request path:', req.path);
console.log('Request method:', req.method);
// Enable CORS for all origins (consider restricting in production)
res.set('Access-Control-Allow-Origin', '*');
res.set('Access-Control-Allow-Methods', 'GET, POST, OPTIONS');
// Ensure 'Content-Type' and 'Authorization' are allowed, plus any custom headers like 'Helicone-Auth'
res.set('Access-Control-Allow-Headers', 'Content-Type, Authorization, Helicone-Auth, Helicone-Session-Id, Helicone-Moderations-Enabled, Helicone-LLM-Security-Enabled, Helicone-Session-Name');
// Handle OPTIONS requests for CORS preflight
if (req.method === 'OPTIONS') {
res.status(204).send('');
return;
}
if (req.path === '/models') {
// Handle requests to /models path
console.log('Handling /models request');
res.status(200).send('Success: /models path hit');
} else if (req.path === '/chat/completions') {
// Handle requests to /chat/completions path
console.log('Handling /chat/completions request');
console.log('Original received payload for /chat/completions:', JSON.stringify(req.body, null, 2));
if (!process.env.OPENROUTER_API_KEY) { // Check for OPENROUTER_API_KEY
console.error('OPENROUTER_API_KEY environment variable is not set.');
res.status(500).send('Server configuration error: Missing API key. Please set the OPENROUTER_API_KEY environment variable.');
return;
}
// Extract response_format.type into session variable, and remove response_format from forwardedBody
let session = null;
const { response_format, ...forwardedBodyWithoutResponseFormat } = req.body;
// Headers for this specific outgoing request
const requestSpecificHeaders = {
'Helicone-Moderations-Enabled': 'true',
'Helicone-LLM-Security-Enabled': 'true',
'Helicone-Session-Name': 'Agent Demo'
};
if (response_format && typeof response_format === 'object' && response_format.type) {
session = response_format.type;
console.log('Extracted session ID (response_format.type):', session);
// Add Helicone-Session-Id to the outgoing headers for this specific request
requestSpecificHeaders['Helicone-Session-Id'] = session;
console.log('Helicone-Session-Id will be added to outgoing request headers:', session);
} else {
console.log('No response_format.type found or response_format is not as expected. Helicone-Session-Id will not be sent.');
}
console.log('Payload after removing "response_format" (if present):', JSON.stringify(forwardedBodyWithoutResponseFormat, null, 2));
// Use the modified forwardedBody for the API call.
const requestBody = forwardedBodyWithoutResponseFormat;
const isStreaming = requestBody.stream === true;
// Prepare options for the client.chat.completions.create call
const clientOptions = {};
if (Object.keys(requestSpecificHeaders).length > 0) {
clientOptions.headers = requestSpecificHeaders;
}
// If you have other per-request options (e.g., query parameters, idempotencyKey), add them to clientOptions.
// clientOptions.query = { ... };
// clientOptions.idempotencyKey = 'my-key';
try {
if (isStreaming) {
// --- Streaming SSE Response using client.chat.completions.create ---
console.log('Streaming request detected. Initiating SSE response.');
console.log('Outgoing request options (stream):', JSON.stringify(clientOptions, null, 2));
const completionStream = await client.chat.completions.create(requestBody, clientOptions);
// Set SSE headers for the response to the client calling this proxy
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
res.setHeader('Connection', 'keep-alive');
res.flushHeaders(); // Send headers immediately
for await (const chunk of completionStream) {
const sseFormattedData = `data: ${JSON.stringify(chunk)}\n\n`;
res.write(sseFormattedData);
// console.log('Sent chunk:', JSON.stringify(chunk, null, 2)); // Verbose: log each sent chunk
}
res.write('data: [DONE]\n\n');
console.log('Stream finished. Sent [DONE].');
res.end(); // End the SSE stream
} else {
// --- Non-Streaming JSON Response using client.chat.completions.create ---
console.log('Non-streaming request detected. Sending full JSON response.');
console.log('Outgoing request options (non-stream):', JSON.stringify(clientOptions, null, 2));
const completion = await client.chat.completions.create(requestBody, clientOptions);
console.log('OpenRouter API response (non-streaming):', JSON.stringify(completion, null, 2));
res.status(200).json(completion);
}
} catch (error) {
console.error('Error during OpenRouter API call:', error.message, error.stack);
if (error.response) { // Axios-like error structure from OpenAI SDK
console.error('OpenRouter API Error Response Status:', error.response.status);
console.error('OpenRouter API Error Response Data:', JSON.stringify(error.response.data, null, 2));
if (!res.headersSent) {
res.status(error.response.status || 500).json(error.response.data || { message: error.message });
} else if (!res.writableEnded) {
res.end(); // End stream if error occurs after headers sent
}
} else if (!res.headersSent) {
res.status(500).send(error.message || 'Error processing your request with OpenRouter');
} else if (!res.writableEnded) {
// Try to send an error event if possible, though this might not always work reliably for streams
try {
const errorPayload = JSON.stringify({ error: { message: error.message || 'Stream error' }});
res.write(`event: error\ndata: ${errorPayload}\n\n`);
console.error('Attempted to send error event to stream.');
} catch (e) {
console.error("Failed to write error event to stream:", e);
}
res.end();
}
}
} else {
// If the path is not recognized, send a 404 Not Found response
console.log(`Path ${req.path} not found`);
res.status(404).send('Not Found: This function only responds to /models and /chat/completions');
}
};