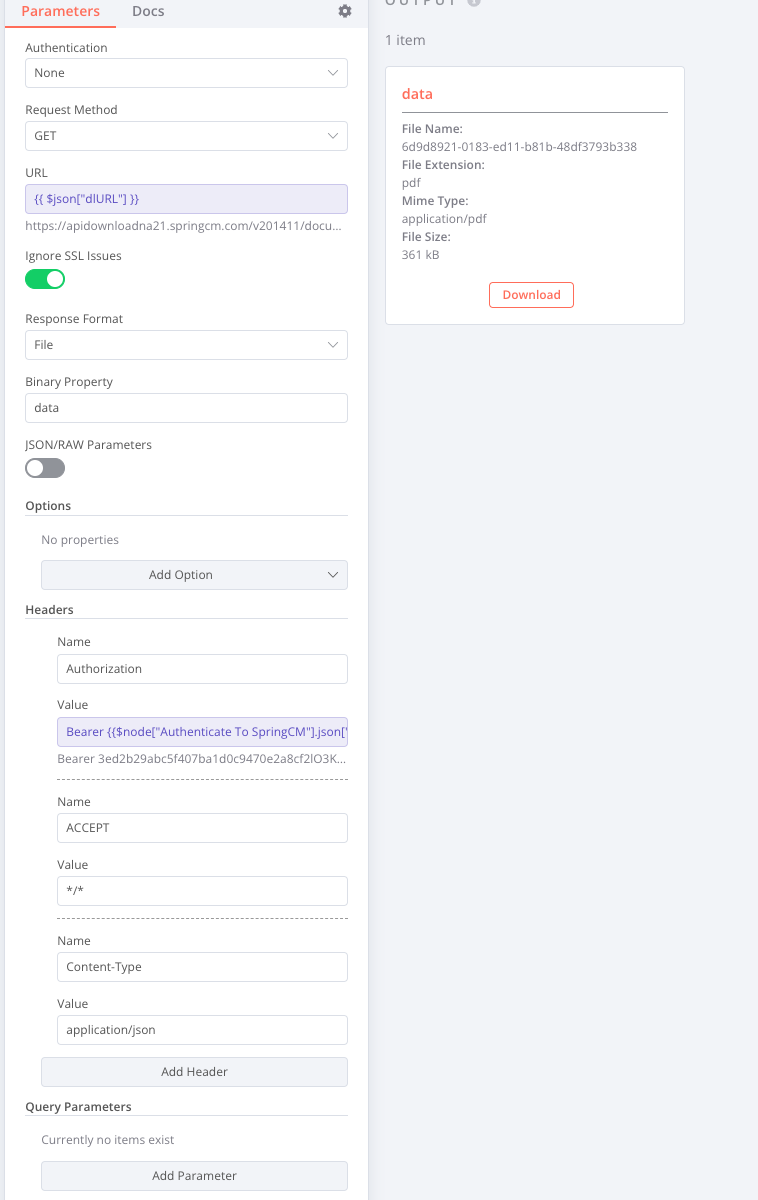
I’m having an issue with the HTTP Request to download a PDF. When I make the call out, it seems to download everything fine, but when I try to preview the document by using the download button it downloads a file, but the file seems to be corrupted and I’m unable to view. I’m able to make the call and download just fine with POSTMAN.
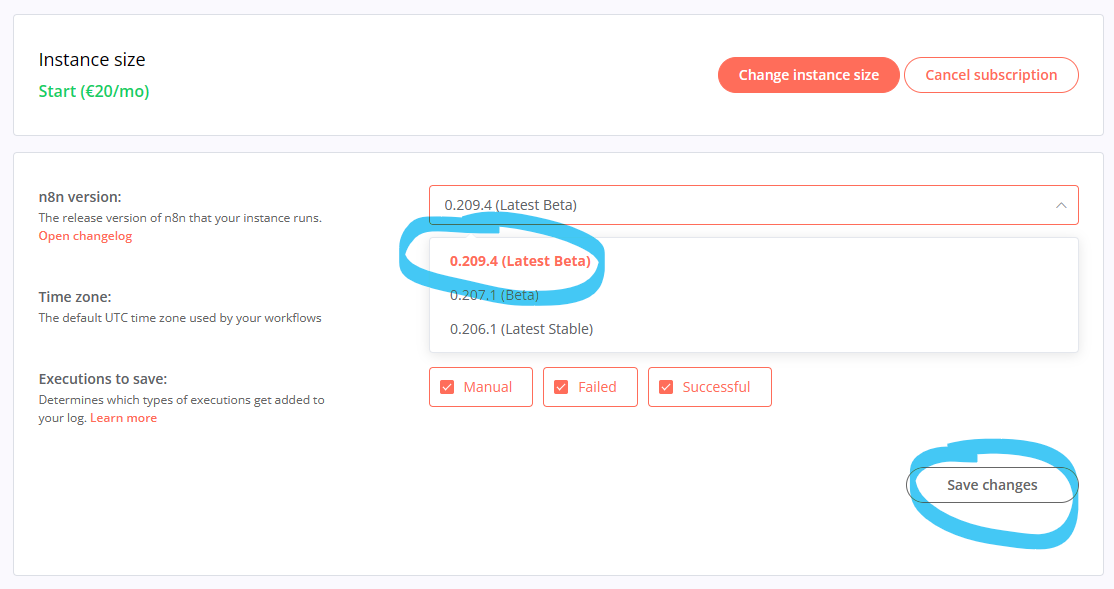
Based on your description I believe you might be encountering a problem fixed in more recent versions of n8n. Can you try upgrading to [email protected] via the n8n cloud dashboard and confirm if the issue still persists?
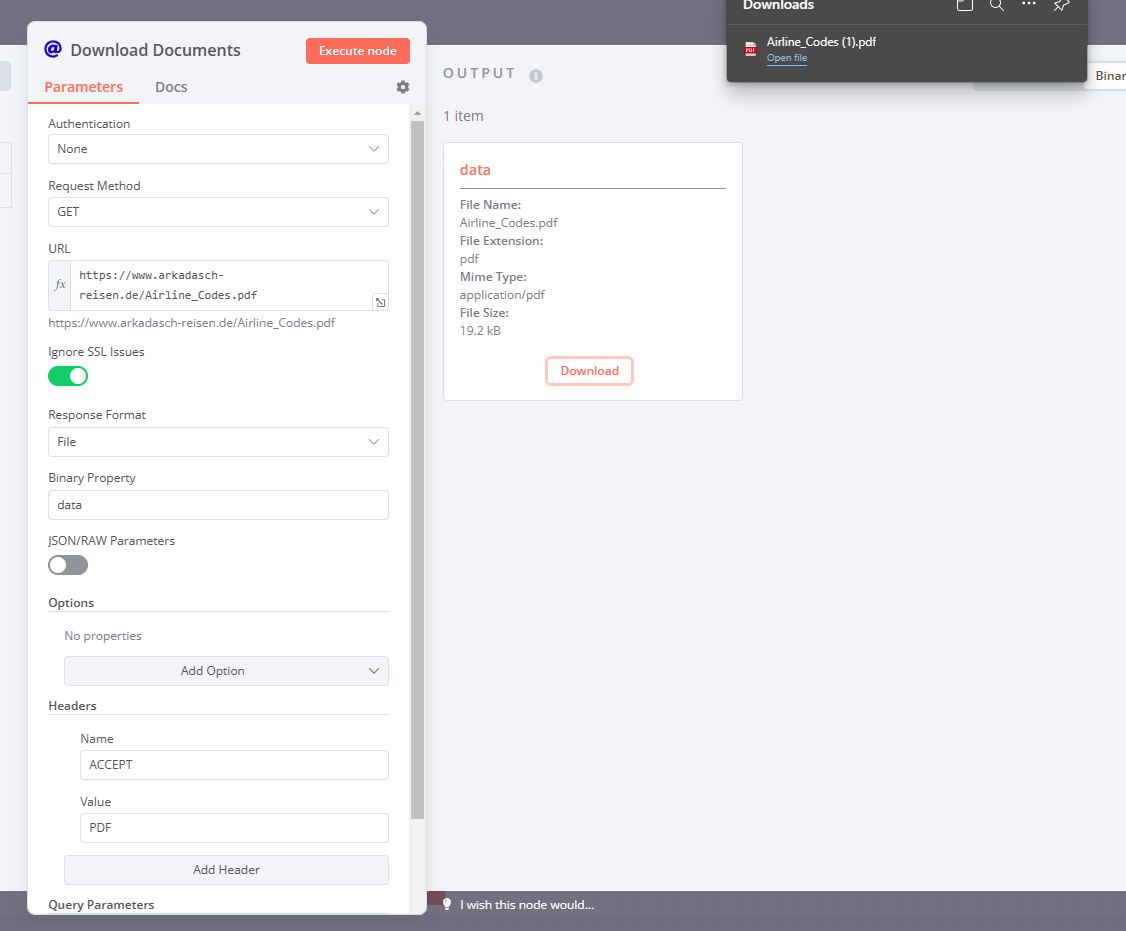
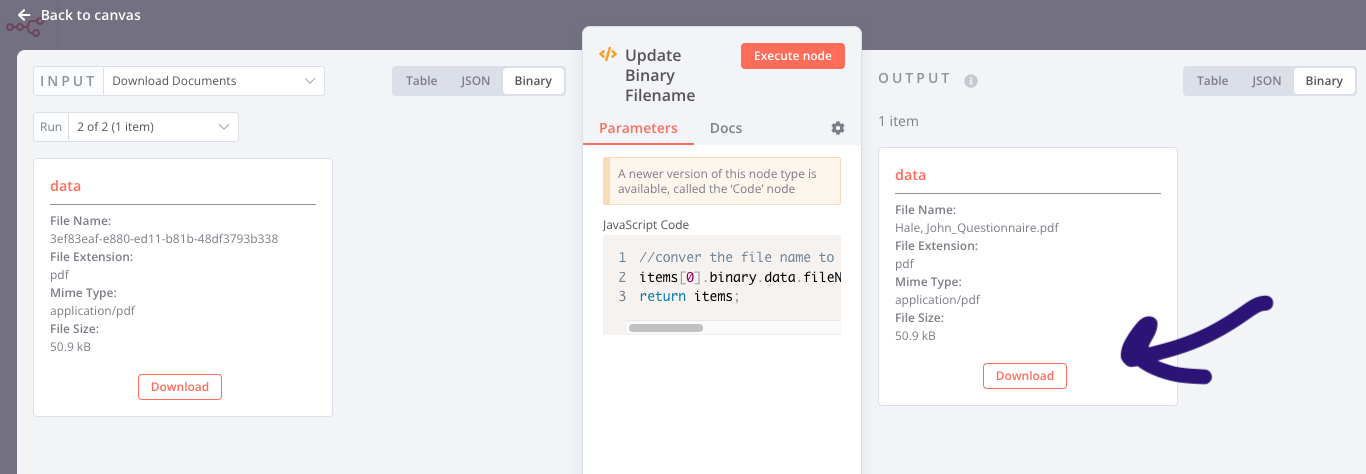
That seems to fix it. Looks like there may be another issue, or I may be doing this wrong, but I’m running a code node to update the file name since it downloads without the .PDF extension, but when I download the output file it still downloads with the original filename.
Hi @Philip_Wiggins, I am glad to hear the download works. I believe the outdated file name might be related to how we process binary data these days and should not affect production executions of the workflow (as in, an email sent with this file for example would have a correctly named file).
Perhaps @netroy can confirm this? I knew he recently worked on this feature.
Hey @Philip_Wiggins
When we create binary data now, we store additional metadata like file-name, file-size, mime-type, etc.
After that when you change the filename in the code node, you are changing the value in an in-memory copy of this data.
If you use this binary data in another node (i.e. to upload the file somewhere) later in the workflow, the updated file-name will be used, but the download currently will use the filename that’s in the metadata when the binary data was created.
If you feel that this behavior is incorrect, then we can add the file-name in the download URL, and then use that file-name for the downloaded file instead.