Hi Guys
Hopefully this is a nice and easy one but i’m struggling to find the answer. I have some folders on our N8N instance that have multiple pdf files in each and i want to upload them to S3.
I can load them in using the read binary files node but during the upload to S3 its just uploading the first file over and over (up to the number of files in the directory)
All the binary contents are called “data”
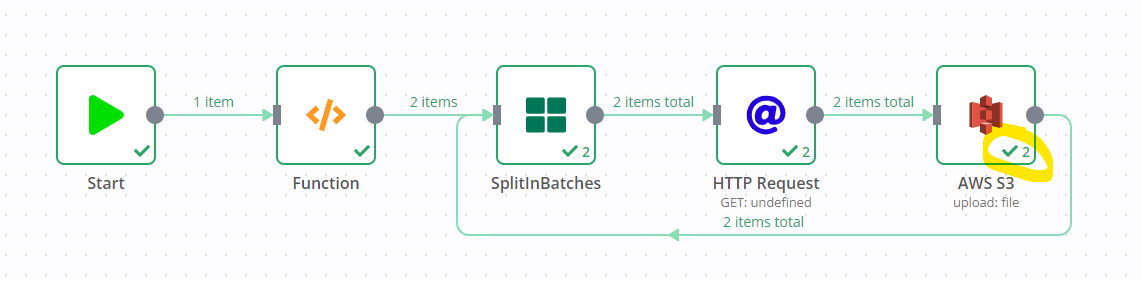
Please find below workflow
Any advice would be appreciated.
Our set-up is N8N (1 node) running in Docker on a t4g.small instance with the default container resource limits.
Database is Postgres running in Docker
Thanks
Hey @messi198310, I’ve just tested your workflow with some slight modifications (since I don’t know the data returned by your db node), but the upload to S3 worked as expected for me.
Two items were returned by my Function node (replacing your db node), and two different items were first downloaded from Unsplash and then uploaded to S3 in two runs, despite both files using the data property:
Can you confirm whether your problem is with the “Read Binary Files” node? E.g. if you remove the MySQL and SplitInBatches part, would the behaviour still remain the same?
Thanks @MutedJam
Doing what you suggested worked.
I think i also know why its not working for me now (just not sure how to fix it yet)
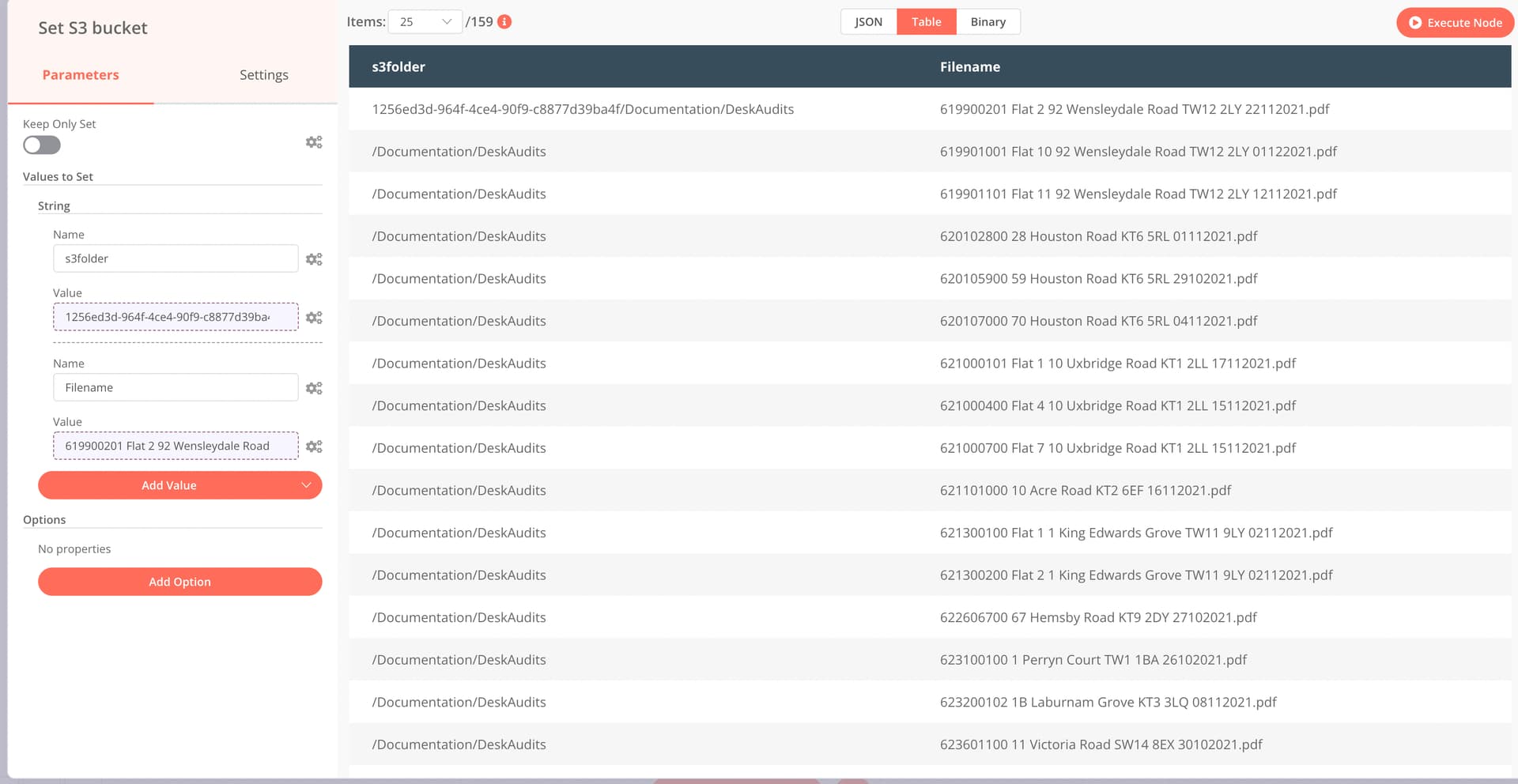
I’m setting the S3 folder and then using it in the upload but because there are only 2 results in SQL return therefore on 2 loops when i set the folder in the S3 bucket node it only sets it for 2 of the files (1 for each run)
Not sure if that makes sense but i think what i need to work out is how i can set the S3 folder for all the files that are returned in the Read PDF Files node.
thanks for you help as always.
Just for the visibility in locating the issue i set the directory meaning i could see what was happening.